
OpenAI 提供了多种管理对话状态的方法,这对于在对话中的多条消息或多轮交互之间保留信息非常重要。
在排查 GPT-5.4 将中间更新视为最终答案的情况时,请验证您的集成是否正确保留了 assistant message
phase 字段。参见 Phase 参数 for details.
手动管理对话状态
虽然每个文本生成请求都是独立且无状态的,您仍然可以通过向文本生成请求提供额外的消息作为参数来实现 多轮对话 。考虑一个“Knock-knock”笑话的场景:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "knock knock."},
{"role": "assistant", "content": "Who's there?"},
{"role": "user", "content": "Orange."},
],
)
print(response.choices[0].message.content)1
2
3
4
5
6
7
8
9
10
11
12
13
14
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4o-mini",
input=[
{"role": "user", "content": "knock knock."},
{"role": "assistant", "content": "Who's there?"},
{"role": "user", "content": "Orange."},
],
)
print(response.output_text)通过使用交替的 user and assistant 消息,您可以在对模型的一次请求中捕获对话的先前状态。
若要跨生成的响应手动共享上下文,请将模型先前的响应输出作为输入包含在内,并将该输入附加到您的下一个请求中。
在以下示例中,我们要求模型讲一个笑话,随后再请求讲另一个笑话。以这种方式将先前的响应附加到新请求中,有助于确保对话感觉自然并保留先前交互的上下文。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from openai import OpenAI
client = OpenAI()
history = [
{
"role": "user",
"content": "tell me a joke"
}
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=history,
)
print(response.choices[0].message.content)
history.append(response.choices[0].message)
history.append({ "role": "user", "content": "tell me another" })
second_response = client.chat.completions.create(
model="gpt-4o-mini",
messages=history,
)
print(second_response.choices[0].message.content)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
from openai import OpenAI
client = OpenAI()
history = [
{
"role": "user",
"content": "tell me a joke"
}
]
response = client.responses.create(
model="gpt-4o-mini",
input=history,
store=False
)
print(response.output_text)
# Add the response to the conversation
history += [{"role": el.role, "content": el.content} for el in response.output]
history.append({ "role": "user", "content": "tell me another" })
second_response = client.responses.create(
model="gpt-4o-mini",
input=history,
store=False
)
print(second_response.output_text)用于管理对话状态的 OpenAI API
我们的 API 让自动管理对话状态变得更加容易,因此您无需在对话的每一轮中手动传递输入。
我们建议使用 Responses API 。因为它是有状态的,所以在跨对话管理上下文只需一个简单的参数即可实现。
如果您正在使用 Chat Completions 端点,则需要如上文所述手动管理状态。
使用 Conversations API
The 对话 API 与 Responses API 配合使用,将对话状态持久化为一个具有自身持久标识符的长期运行对象。创建对话对象后,您可以跨会话、设备或作业继续使用它。
对话存储项目,这些项目可以是消息、工具调用、工具输出和其他数据。
1
conversation = openai.conversations.create()在多轮交互中,您可以传递 conversation 以便在后续响应中保持状态并跨后续响应共享上下文,而无需将多个响应项链接在一起。
1
2
3
4
5
response = openai.responses.create(
model="gpt-4.1",
input=[{"role": "user", "content": "What are the 5 Ds of dodgeball?"}],
conversation="conv_689667905b048191b4740501625afd940c7533ace33a2dab"
)从先前的响应中传递上下文
管理会话状态的另一种方法是使用跨生成的响应共享上下文,通过 previous_response_id 参数来实现。该参数允许你将响应链接起来,从而创建一个线索式的对话。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4o-mini",
input="tell me a joke",
)
print(response.output_text)
second_response = client.responses.create(
model="gpt-4o-mini",
previous_response_id=response.id,
input=[{"role": "user", "content": "explain why this is funny."}],
)
print(second_response.output_text)在以下示例中,我们要求模型讲个笑话。然后,我们单独要求模型解释它为什么好笑,由于模型拥有所有必要的上下文,因此能够提供出色的响应。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4o-mini",
input="tell me a joke",
)
print(response.output_text)
second_response = client.responses.create(
model="gpt-4o-mini",
previous_response_id=response.id,
input=[{"role": "user", "content": "explain why this is funny."}],
)
print(second_response.output_text)previous_response_id in WebSocket mode
如果你正在使用 Responses API WebSocket 模式,继续生成使用相同的 previous_response_id 其语义与 HTTP 模式相同,但通过持久性套接字进行重复 response.create events.
连接本地缓存目前会将最近的上一次响应保存在内存中,以实现低延迟的续接。如果无法解析未缓存的 ID,请使用 previous_response_id 进行上传,并将其设置为 null 发送一个新的轮次,并传入完整的输入上下文。
即使在使用 previous_response_id,链式响应中所有先前的输入 token 都将作为 API 中的输入 token 计费。
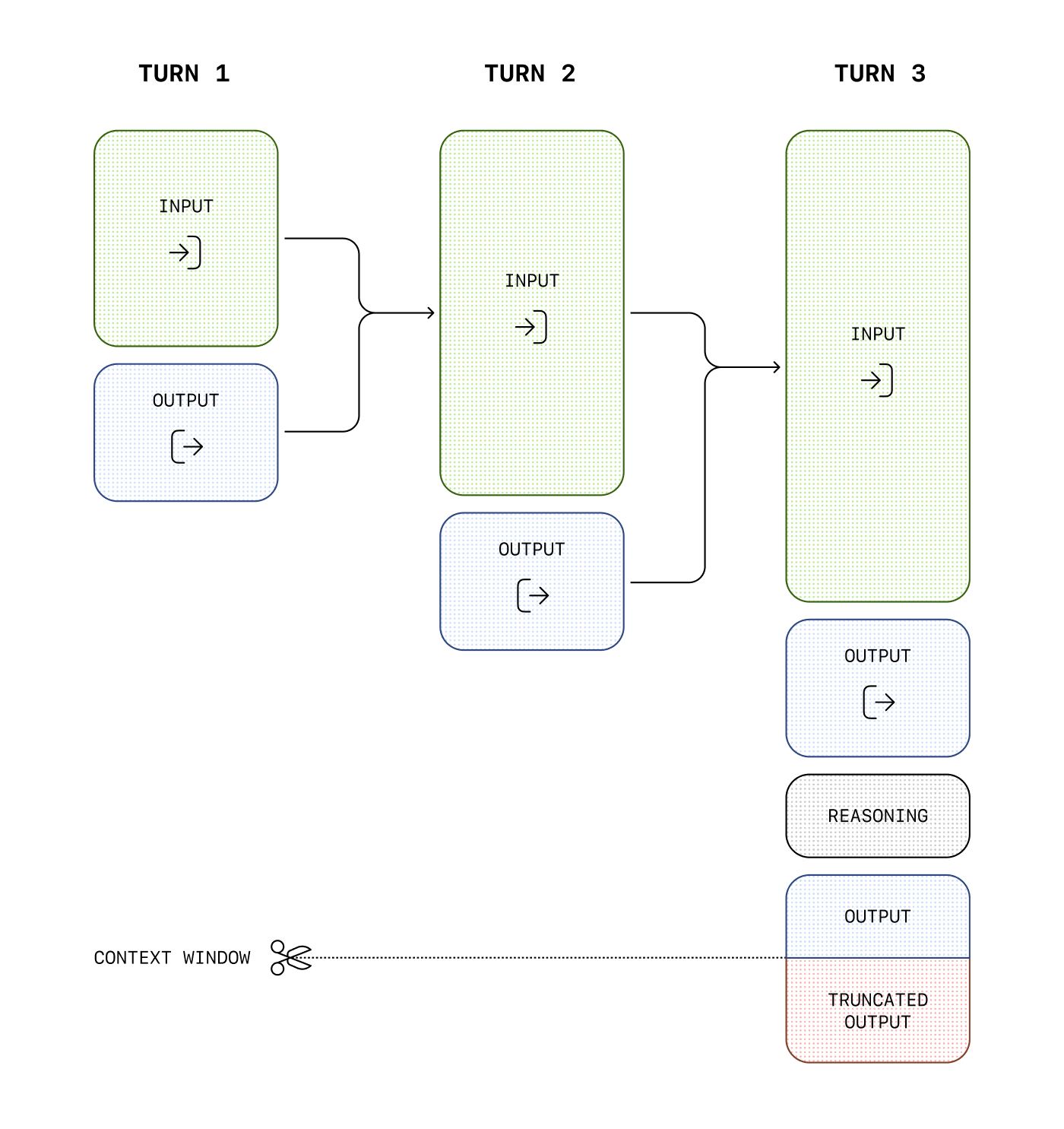
管理上下文窗口
理解上下文窗口将有助于你成功创建线索式对话,并管理跨模型交互的状态。
The 上下文窗口 是单个请求中可使用的最大 token 数量。该最大 token 数包括输入、输出和推理 token。要了解你所用模型的上下文窗口,请参阅 模型详情.
管理文本生成的上下文
随着输入变得更复杂,或者在对话中包含更多轮次时,你需要同时考虑 输出 token and 上下文窗口 限制。模型输入和输出以 token,它们从输入中解析以分析其内容和意图,并组装以呈现逻辑输出。模型在文本生成请求的生命周期内具有 token 使用限制。
- 进行计量。输出 token 是模型响应提示词生成的 token。每个模型具有不同的 输出 token 限制。例如,
gpt-4o-2024-08-06最多可生成 16,384 个输出 token。 - A 上下文窗口 描述了可用于输入和输出 token 的总 token 数(对于某些模型,还包括 推理 token)。比较我们模型的 上下文窗口限制 。例如,
gpt-4o-2024-08-06具有 128k token 的总上下文窗口。
如果你创建了非常大的提示词——通常是通过为模型包含额外的上下文、数据或示例——你可能会面临超出模型分配上下文窗口的风险,这可能会导致输出被截断。
使用 分词器工具,使用 tiktoken 库,以查看特定文本字符串中有多少 token。
例如,当向其发出 API 请求时 Chat Completions with the o1 模型,以下 token 计数将计入上下文窗口总数:
- 输入 token(你包含在
messages数组中 Chat Completions) - 输出 token(根据你的提示词生成的 token)
- 推理 token(由模型用于规划响应)
例如,当向 Responses API 发起带有推理功能的模型的 API 请求时(如 o1 模型,以下 token 计数将计入上下文窗口总数:
- 输入 token(你包含在
input数组中的 Responses API) - 输出 token(根据你的提示词生成的 token)
- 推理 token(由模型用于规划响应)
超出上下文窗口限制的 Token 可能会在 API 响应中被截断。
你可以使用 分词器工具.
压缩
详细的压缩指南现在位于 压缩.
- For
/responseswithcontext_managementandcompact_threshold,请参见 服务端压缩. - 有关显式压缩控制,请参见
独立的压缩端点
and the
/responses/compactAPI 参考.
后续步骤
有关更具体的示例和用例,请访问 OpenAI Cookbook,或了解更多关于使用 API 扩展模型功能的信息: