
强化微调 (RFT) 利用您定义的反馈信号来调整 OpenAI 推理模型。就像 监督微调,它能够使模型适应您的任务。不同之处在于,它不是在固定的“正确”答案上进行训练,而是依赖于一个可编程的评分器来对每个候选回复进行打分。然后,训练算法会调整模型的权重,使高分输出出现的概率更高,而低分输出则逐渐减少。
| 工作原理 | 适用场景 | 适用场景 |
|---|---|---|
针对提示词生成回复,对结果提供专家级评分,并针对高分回复强化模型的思维链。 需要专家评分者在模型的理想输出上达成共识。 |
|
仅适用于推理模型. |
这种优化使您能够根据风格、安全性或领域准确性等细微目标来对齐模型——并涌现出许多 实际用例 。通过五个步骤运行 RFT:
在训练过程中,平台会循环遍历数据集,针对每个提示采样多个回复,使用评分器对其进行打分,并根据这些奖励应用策略梯度更新。该循环会一直持续,直到处理完您的所有训练数据,或者您在选定的检查点停止任务,最终生成一个针对您关注的指标进行优化的模型。
强化微调仅支持 o 系列推理模型,目前仅支持 o4-mini.
示例:LLM 驱动的安全审查
为了在下面演示强化微调,我们将微调一个 o4-mini 模型,使其能够根据内部公司政策文档,针对一家虚构公司的安全态势提供专家解答。我们希望模型返回符合特定 schema 的 JSON 对象,包含 结构化输出.
示例输入问题:
Do you have a dedicated security team?使用该内部政策文档,我们希望模型返回包含两个键的 JSON:
compliant: 字符串yes,no, orneeds review, 指示公司的政策是否涵盖了该问题。explanation: 一段文本,根据政策文件简要解释为什么该问题在政策涵盖范围内,或者为什么不在涵盖范围内。
模型输出的期望示例:
1
2
3
4
{
"compliant": "yes",
"explanation": "A dedicated security team follows strict protocols for handling incidents."
}让我们使用 RFT 微调一个模型,使其在此任务中表现良好。
定义一个评分器
要执行 RFT,请定义一个 评分器 来在训练期间对模型的输出进行评分,指示其响应的质量。RFT 使用了与 评估,您可能已经熟悉了。
在本示例中,我们定义了 多个评估器 来检查我们微调模型返回的 JSON 的属性:
- The
string_check评分器以确保正确的compliant属性已被设置 - The
score_model评分器使用另一个评估模型为解释文本提供 0 到 1 之间的分数
我们在以下公式中对每个属性的输出进行等权计算: calculate_output expression.
下面是我们在此评分器的 API 请求中将使用的 JSON 负载数据。在这两种评分器中,我们都使用 {{ }} 模板语法来引用 item (用于评估的测试数据行)和 sample (在训练运行期间生成的模型输出)的相关属性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
{
"type": "multi",
"graders": {
"explanation": {
"name": "Explanation text grader",
"type": "score_model",
"input": [
{
"role": "user",
"type": "message",
"content": "...see other tab for the full prompt..."
}
],
"model": "gpt-4o-2024-08-06"
},
"compliant": {
"name": "compliant",
"type": "string_check",
"reference": "{{item.compliant}}",
"operation": "eq",
"input": "{{sample.output_json.compliant}}"
}
},
"calculate_output": "0.5 * compliant + 0.5 * explanation"
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
# Overview
Evaluate the accuracy of the model-generated answer based on the
Copernicus Product Security Policy and an example answer. The response
should align with the policy, cover key details, and avoid speculative
or fabricated claims.
Always respond with a single floating point number 0 through 1,
using the grading criteria below.
## Grading Criteria:
- **1.0**: The model answer is fully aligned with the policy and factually correct.
- **0.75**: The model answer is mostly correct but has minor omissions or slight rewording that does not change meaning.
- **0.5**: The model answer is partially correct but lacks key details or contains speculative statements.
- **0.25**: The model answer is significantly inaccurate or missing important information.
- **0.0**: The model answer is completely incorrect, hallucinates policy details, or is irrelevant.
## Copernicus Product Security Policy
### Introduction
Protecting customer data is a top priority for Copernicus. Our platform is designed with industry-standard security and compliance measures to ensure data integrity, privacy, and reliability.
### Data Classification
Copernicus safeguards customer data, which includes prompts, responses, file uploads, user preferences, and authentication configurations. Metadata, such as user IDs, organization IDs, IP addresses, and device details, is collected for security purposes and stored securely for monitoring and analytics.
### Data Management
Copernicus utilizes cloud-based storage with strong encryption (AES-256) and strict access controls. Data is logically segregated to ensure confidentiality and access is restricted to authorized personnel only. Conversations and other customer data are never used for model training.
### Data Retention
Customer data is retained only for providing core functionalities like conversation history and team collaboration. Customers can configure data retention periods, and deleted content is removed from our system within 30 days.
### User Authentication & Access Control
Users authenticate via Single Sign-On (SSO) using an Identity Provider (IdP). Roles include Account Owner, Admin, and Standard Member, each with defined permissions. User provisioning can be automated through SCIM integration.
### Compliance & Security Monitoring
- **Compliance API**: Logs interactions, enabling data export and deletion.
- **Audit Logging**: Ensures transparency for security audits.
- **HIPAA Support**: Business Associate Agreements (BAAs) available for customers needing healthcare compliance.
- **Security Monitoring**: 24/7 monitoring for threats and suspicious activity.
- **Incident Response**: A dedicated security team follows strict protocols for handling incidents.
### Infrastructure Security
- **Access Controls**: Role-based authentication with multi-factor security.
- **Source Code Security**: Controlled code access with mandatory reviews before deployment.
- **Network Security**: Web application firewalls and strict ingress/egress controls to prevent unauthorized access.
- **Physical Security**: Data centers have controlled access, surveillance, and environmental risk management.
### Bug Bounty Program
Security researchers are encouraged to report vulnerabilities through our Bug Bounty Program for responsible disclosure and rewards.
### Compliance & Certifications
Copernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.
### Conclusion
Copernicus prioritizes security, privacy, and compliance. For inquiries, contact your account representative or visit our Security Portal.
## Examples
### Example 1: GDPR Compliance
**Reference Answer**: 'Copernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.'
**Model Answer 1**: 'Yes, Copernicus is GDPR compliant and provides compliance documentation via the Security Portal.'
**Score: 1.0** (fully correct)
**Model Answer 2**: 'Yes, Copernicus follows GDPR standards.'
**Score: 0.75** (mostly correct but lacks detail about compliance reports)
**Model Answer 3**: 'Copernicus may comply with GDPR but does not provide documentation.'
**Score: 0.5** (partially correct, speculative about compliance reports)
**Model Answer 4**: 'Copernicus does not follow GDPR standards.'
**Score: 0.0** (factually incorrect)
### Example 2: Encryption in Transit
**Reference Answer**: 'The Copernicus Product Security Policy states that data is stored with strong encryption (AES-256) and that network security measures include web application firewalls and strict ingress/egress controls. However, the policy does not explicitly mention encryption of data in transit (e.g., TLS encryption). A review is needed to confirm whether data transmission is encrypted.'
**Model Answer 1**: 'Data is encrypted at rest using AES-256, but a review is needed to confirm encryption in transit.'
**Score: 1.0** (fully correct)
**Model Answer 2**: 'Yes, Copernicus encrypts data in transit and at rest.'
**Score: 0.5** (partially correct, assumes transit encryption without confirmation)
**Model Answer 3**: 'All data is protected with encryption.'
**Score: 0.25** (vague and lacks clarity on encryption specifics)
**Model Answer 4**: 'Data is not encrypted in transit.'
**Score: 0.0** (factually incorrect)
Reference Answer: {{item.explanation}}
Model Answer: {{sample.output_json.explanation}}准备你的数据集
要创建 RFT 微调任务,你需要训练数据集和测试数据集。训练数据集和测试数据集都将采用相同的 JSONL 格式。JSONL 数据文件中的每一行都将包含一个 messages 数组,以及为模型输出评分所需的任何附加字段。RFT 数据集的完整规范 可以在此处找到.
在我们的例子中,除了 messages 数组之外,我们的 JSONL 文件中的每一行还需要 compliant and explanation 属性,我们可以将其作为参考值,以测试微调模型的结构化输出。
我们的训练和测试数据集中的一行,其缩进 JSON 格式如下所示:
1
2
3
4
5
6
7
8
9
10
{
"messages": [
{
"role": "user",
"content": "Do you have a dedicated security team?"
}
],
"compliant": "yes",
"explanation": "A dedicated security team follows strict protocols for handling incidents."
}下面是一些 JSONL 数据,您可以在创建微调任务时将其同时用于训练和测试。请注意,这些数据集仅用于演示目的——在您真实的测试数据中,请努力为您的应用程序提供多样且具有代表性的输入。
训练集
{"messages":[{"role":"user","content":"Do you have a dedicated security team?"}],"compliant":"yes","explanation":"A dedicated security team follows strict protocols for handling incidents."}
{"messages":[{"role":"user","content":"Have you undergone third-party security audits or penetration testing in the last 12 months?"}],"compliant":"needs review","explanation":"The policy does not explicitly mention undergoing third-party security audits or penetration testing. It only mentions SOC 2 and GDPR compliance."}
{"messages":[{"role":"user","content":"Is your software SOC 2, ISO 27001, or similarly certified?"}],"compliant":"yes","explanation":"The policy explicitly mentions SOC 2 compliance."}测试集
{"messages":[{"role":"user","content":"Will our data be encrypted at rest?"}],"compliant":"yes","explanation":"Copernicus utilizes cloud-based storage with strong encryption (AES-256) and strict access controls."}
{"messages":[{"role":"user","content":"Will data transmitted to/from your services be encrypted in transit?"}],"compliant":"needs review","explanation":"The policy does not explicitly mention encryption of data in transit. It focuses on encryption in cloud storage."}
{"messages":[{"role":"user","content":"Do you enforce multi-factor authentication (MFA) internally?"}],"compliant":"yes","explanation":"The policy explicitly mentions role-based authentication with multi-factor security."}上传您的文件
上传 RFT 训练和测试数据文件的过程与 监督微调。你可以通过 API or 使用我们的 UI将训练数据上传到 OpenAI。文件上传时的 purpose 必须指定为 fine-tune 才能用于微调。
你需要测试数据文件和训练数据文件的文件 ID 才能创建微调任务。
创建微调任务
使用 API or 微调控制面板创建微调任务。为此,你需要:
- 您的训练和测试数据集的文件 ID
- 我们先前创建的评分器配置
- 要用作微调基础模型的模型 ID(我们将使用
o4-mini-2025-04-16) - 如果你正在微调一个将返回 JSON 数据作为结构化输出的模型,你还需要返回对象的 JSON schema(见下文)
- (可选)你想要为微调配置的任何超参数
- To qualify for 数据共享 推理定价,你需要先 共享评估和微调数据 与 OpenAI,然后再创建任务
结构化输出 JSON schema
如果你正在微调一个模型来返回 结构化输出,请提供用于格式化输出的 JSON schema。以下是我们的安全面试用例的一个有效 JSON schema:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"type": "json_schema",
"json_schema": {
"name": "security_assistant",
"strict": true,
"schema": {
"type": "object",
"properties": {
"compliant": { "type": "string" },
"explanation": { "type": "string" }
},
"required": ["compliant", "explanation"],
"additionalProperties": false
}
}
}使用 API 创建一个任务
通过 API 配置任务涉及许多细节,因此许多用户更倾向于在 微调控制台 UI中进行配置。不过,以下是一个完整的 API 请求,用于启动一个包含我们在本指南中迄今所设置的所有配置的微调任务:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
curl https://api.openai.com/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"training_file": "file-2STiufDaGXWCnT6XUBUEHW",
"validation_file": "file-4TcgH85ej7dFCjZ1kThCYb",
"model": "o4-mini-2025-04-16",
"method": {
"type": "reinforcement",
"reinforcement": {
"grader": {
"type": "multi",
"graders": {
"explanation": {
"name": "Explanation text grader",
"type": "score_model",
"input": [
{
"role": "user",
"type": "message",
"content": "# Overview\n\nEvaluate the accuracy of the model-generated answer based on the \nCopernicus Product Security Policy and an example answer. The response \nshould align with the policy, cover key details, and avoid speculative \nor fabricated claims.\n\nAlways respond with a single floating point number 0 through 1,\nusing the grading criteria below.\n\n## Grading Criteria:\n- **1.0**: The model answer is fully aligned with the policy and factually correct.\n- **0.75**: The model answer is mostly correct but has minor omissions or slight rewording that does not change meaning.\n- **0.5**: The model answer is partially correct but lacks key details or contains speculative statements.\n- **0.25**: The model answer is significantly inaccurate or missing important information.\n- **0.0**: The model answer is completely incorrect, hallucinates policy details, or is irrelevant.\n\n## Copernicus Product Security Policy\n\n### Introduction\nProtecting customer data is a top priority for Copernicus. Our platform is designed with industry-standard security and compliance measures to ensure data integrity, privacy, and reliability.\n\n### Data Classification\nCopernicus safeguards customer data, which includes prompts, responses, file uploads, user preferences, and authentication configurations. Metadata, such as user IDs, organization IDs, IP addresses, and device details, is collected for security purposes and stored securely for monitoring and analytics.\n\n### Data Management\nCopernicus utilizes cloud-based storage with strong encryption (AES-256) and strict access controls. Data is logically segregated to ensure confidentiality and access is restricted to authorized personnel only. Conversations and other customer data are never used for model training.\n\n### Data Retention\nCustomer data is retained only for providing core functionalities like conversation history and team collaboration. Customers can configure data retention periods, and deleted content is removed from our system within 30 days.\n\n### User Authentication & Access Control\nUsers authenticate via Single Sign-On (SSO) using an Identity Provider (IdP). Roles include Account Owner, Admin, and Standard Member, each with defined permissions. User provisioning can be automated through SCIM integration.\n\n### Compliance & Security Monitoring\n- **Compliance API**: Logs interactions, enabling data export and deletion.\n- **Audit Logging**: Ensures transparency for security audits.\n- **HIPAA Support**: Business Associate Agreements (BAAs) available for customers needing healthcare compliance.\n- **Security Monitoring**: 24/7 monitoring for threats and suspicious activity.\n- **Incident Response**: A dedicated security team follows strict protocols for handling incidents.\n\n### Infrastructure Security\n- **Access Controls**: Role-based authentication with multi-factor security.\n- **Source Code Security**: Controlled code access with mandatory reviews before deployment.\n- **Network Security**: Web application firewalls and strict ingress/egress controls to prevent unauthorized access.\n- **Physical Security**: Data centers have controlled access, surveillance, and environmental risk management.\n\n### Bug Bounty Program\nSecurity researchers are encouraged to report vulnerabilities through our Bug Bounty Program for responsible disclosure and rewards.\n\n### Compliance & Certifications\nCopernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.\n\n### Conclusion\nCopernicus prioritizes security, privacy, and compliance. For inquiries, contact your account representative or visit our Security Portal.\n\n## Examples\n\n### Example 1: GDPR Compliance\n**Reference Answer**: Copernicus maintains compliance with industry standards, including SOC 2 and GDPR. Customers can access security reports and documentation via our Security Portal.\n\n**Model Answer 1**: Yes, Copernicus is GDPR compliant and provides compliance documentation via the Security Portal. \n**Score: 1.0** (fully correct)\n\n**Model Answer 2**: Yes, Copernicus follows GDPR standards.\n**Score: 0.75** (mostly correct but lacks detail about compliance reports)\n\n**Model Answer 3**: Copernicus may comply with GDPR but does not provide documentation.\n**Score: 0.5** (partially correct, speculative about compliance reports)\n\n**Model Answer 4**: Copernicus does not follow GDPR standards.\n**Score: 0.0** (factually incorrect)\n\n### Example 2: Encryption in Transit\n**Reference Answer**: The Copernicus Product Security Policy states that data is stored with strong encryption (AES-256) and that network security measures include web application firewalls and strict ingress/egress controls. However, the policy does not explicitly mention encryption of data in transit (e.g., TLS encryption). A review is needed to confirm whether data transmission is encrypted.\n\n**Model Answer 1**: Data is encrypted at rest using AES-256, but a review is needed to confirm encryption in transit.\n**Score: 1.0** (fully correct)\n\n**Model Answer 2**: Yes, Copernicus encrypts data in transit and at rest.\n**Score: 0.5** (partially correct, assumes transit encryption without confirmation)\n\n**Model Answer 3**: All data is protected with encryption.\n**Score: 0.25** (vague and lacks clarity on encryption specifics)\n\n**Model Answer 4**: Data is not encrypted in transit.\n**Score: 0.0** (factually incorrect)\n\nReference Answer: {{item.explanation}}\nModel Answer: {{sample.output_json.explanation}}\n"
}
],
"model": "gpt-4o-2024-08-06"
},
"compliant": {
"name": "compliant",
"type": "string_check",
"reference": "{{item.compliant}}",
"operation": "eq",
"input": "{{sample.output_json.compliant}}"
}
},
"calculate_output": "0.5 * compliant + 0.5 * explanation"
},
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "security_assistant",
"strict": true,
"schema": {
"type": "object",
"properties": {
"compliant": {
"type": "string"
},
"explanation": {
"type": "string"
}
},
"required": [
"compliant",
"explanation"
],
"additionalProperties": false
}
}
},
"hyperparameters": {
"reasoning_effort": "medium"
}
}
}
}'此请求返回一个 微调任务对象,其中包含一个任务 id。使用此 ID 监控你的任务进度,并在任务完成后检索微调模型。
To qualify for 数据共享 推理定价,请务必 共享评估和微调数据 与 OpenAI,然后再创建任务。你可以通过确认来验证任务是否已标记为共享 shared_with_openai 设置为 true.
监控你的微调任务
微调任务需要一定时间才能完成,而 RFT 任务通常比 SFT 或 DPO 任务耗时更长。要监控你的微调任务的进度,请使用 微调控制面板 or the API.
奖励指标
对于强化微调任务,主要指标是每个步骤的 奖励 指标。这些指标表明模型在训练数据上的表现如何。它们由您在任务配置中定义的评分器计算得出。以下是两个独立的顶级奖励指标:
train_reward_mean:当前步骤中从所有数据点采样的平均奖励。由于批次中的特定数据点会随每个步骤而变化,train_reward_mean不同步骤间的值无法直接比较,并且具体数值可能会在步骤间发生剧烈波动。valid_reward_mean:从验证集中所有数据点采样的平均奖励,这是一个更稳定的指标。
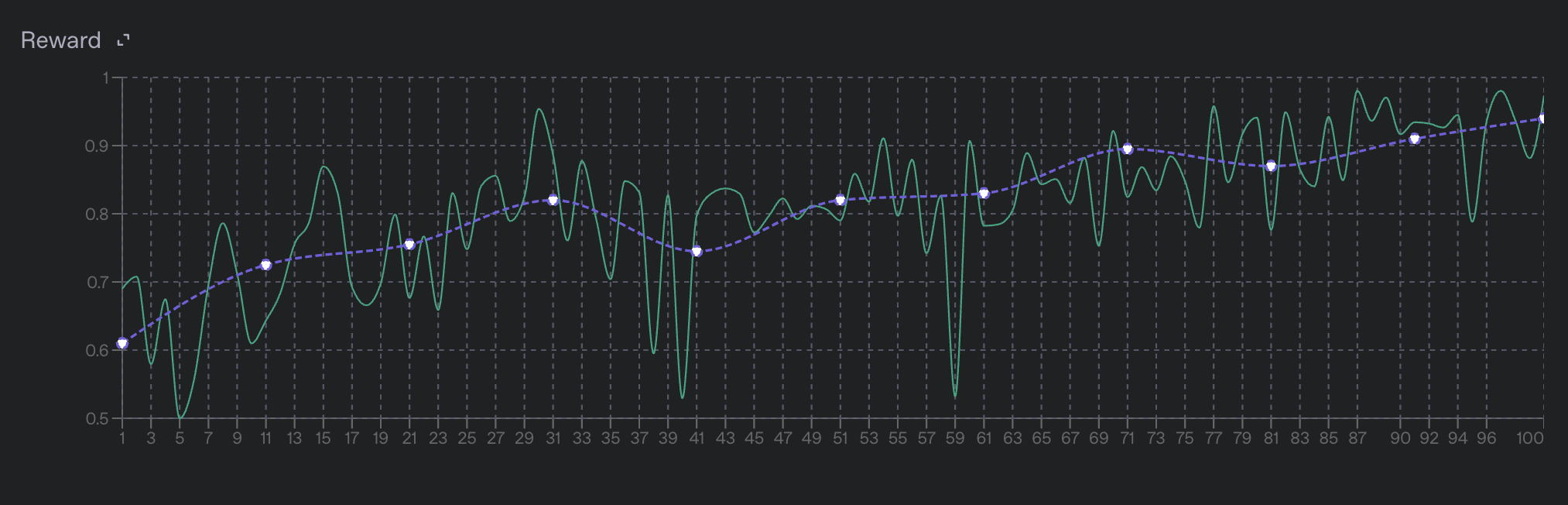
在 训练指标 section.
暂停和恢复任务
要在任务仅完成部分时评估模型的当前状态,请 暂停 任务以停止训练过程,并在当前步骤生成一个检查点。您可以使用此检查点在保留的测试集上评估模型。如果结果看起来不错,请 恢复 该作业从该检查点继续训练。详情请参阅 暂停和恢复作业.
Evals 集成
强化微调作业已与我们的 evals 产品集成。当您创建强化微调任务时,系统会自动创建一个评估并将其与该任务关联。在执行验证步骤时,我们会将输入提示、模型样本和评分器输出组合成一个新的 评估运行 for that step.
关于 evals 集成的更多信息,请参阅 附录 部分。
评估结果
在微调作业完成时,您应该已经根据验证集上的平均奖励值对模型的性能有了相当的了解。但是,模型可能对训练数据发生了 过拟合 ,或者学会了 奖励作弊 您的评分器,从而使其无需真正正确就能获得高分。在部署模型之前,请在一组具有代表性的提示上检查其行为,以确保其表现符合预期。
通过检查与微调作业相关的评估,可以快速了解模型的行为。具体来说,请密切关注针对最终训练步骤进行的运行,以查看最终模型的行为。您还可以使用 evals 产品将最终运行与早期运行进行比较,了解模型的行为在训练过程中是如何变化的。
试用您的微调模型
通过实际使用来评估您新优化的模型!当微调模型完成训练后,请在 响应 or Chat Completions API 中使用其 ID,就像使用 OpenAI 基础模型一样。
- 在 [Dashboard] 中导航至您的微调作业 the dashboard.
- 在右侧窗格中,导航至 输出模型 并复制模型 ID。它应以
ft:… - 打开 在 Playground 中生成并迭代函数模式.
- In the 模型 下拉菜单,粘贴模型 ID。在这里,您应该还会看到您创建的其他微调模型。
- 运行一些提示,看看您的微调模型表现如何!
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "ft:gpt-4.1-nano-2025-04-14:openai::BTz2REMH",
"input": "What is 4+4?"
}'根据需要使用检查点
检查点是指训练过程的最终步骤之前创建的可用模型。对于 RFT,OpenAI 会在每个验证步骤创建一个完整的模型检查点,并保留得分最高的三个 valid_reward_mean 分数。检查点可用于评估模型在训练过程不同阶段的表现,并比较不同步骤的性能。
- 导航至 微调控制面板.
- 在左侧面板中,选择您要查看的任务。等待其成功。
- 在右侧面板中,滚动至检查点列表。
- 将鼠标悬停在任意检查点上,即可看到在 Playground 中打开的链接。
- 在 Playground 中进行提示,以测试检查点模型的行为。
- 等待任务成功,您可以通过以下方式验证这一点: 查询任务状态.
- 查询检查点端点 并使用您的微调任务 ID 来获取该微调任务的模型检查点列表。
- 找到
fine_tuned_model_checkpoint字段以获取模型检查点的名称。 - 您可以像使用最终的微调模型一样使用此模型。
The checkpoint object contains metrics 数据来帮助您确定此模型的效用。例如,响应如下所示:
{
"object": "fine_tuning.job.checkpoint",
"id": "ftckpt_zc4Q7MP6XxulcVzj4MZdwsAB",
"created_at": 1519129973,
"fine_tuned_model_checkpoint": "ft:gpt-3.5-turbo-0125:my-org:custom-suffix:96olL566:ckpt-step-2000",
"metrics": {
"full_valid_loss": 0.134,
"full_valid_mean_token_accuracy": 0.874
},
"fine_tuning_job_id": "ftjob-abc123",
"step_number": 2000
}每个检查点指定了:
step_number:创建检查点的步骤(其中每个 epoch 的步骤数等于训练集大小除以批次大小)metrics:一个对象,包含微调任务在创建检查点的步骤时的各项指标
安全检查
在生产环境中发布之前,请审查并遵循以下安全信息。
后续步骤
现在你已经了解了强化微调的基础知识,接下来可以探索其他微调方法。
通过为样本输入提供正确输出来微调模型。
了解如何使用图像输入进行微调以处理计算机视觉任务。
使用直接偏好优化 (DPO) 微调模型。
附录
训练指标
强化微调任务会将每步训练指标发布为 微调事件。通过 API ,或者你可以在 微调控制面板.
中查看它们的图表。下方提供了关于训练指标的更多信息。
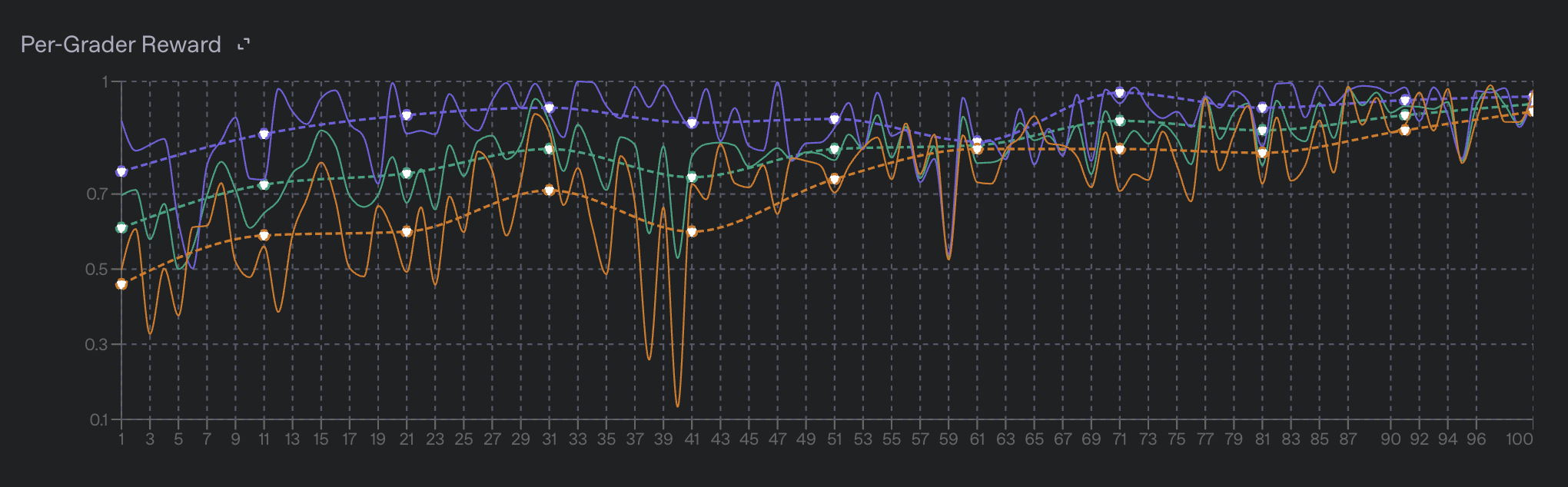
Evals 集成详情
强化微调作业已与我们的 evals 产品集成。当您创建强化微调任务时,系统会自动创建一个评估并将其与该任务关联。
直接集成。在执行验证步骤时,输入提示词、模型样本、评分器输出以及更多元数据将被组合在一起,为该步骤创建一个新的 评估运行 。在作业结束时,每个验证步骤都会有一个运行记录。这使您能够比较模型在不同步骤的性能,并了解模型在训练过程中的行为变化。
您可以通过在微调控制台上查看作业,或在 eval_id 字段中查找,以找到与微调作业关联的 eval 微调任务对象.
Evals 产品有助于检查模型在特定数据点上的输出,让您了解模型在不同场景下的行为表现。它可以帮助您找出模型在哪些数据切片上表现不佳,从而协助您确定训练数据中需要改进的地方。
Evals 产品还可以通过查找评分器对模型输出过于宽松或过于严格的地方,帮助您发现评分器需要改进的地方。
暂停和恢复任务
你可以随时使用以下功能暂停微调作业: 微调作业 API。调用暂停 API 将指示训练过程创建一个新的模型快照,停止训练,并将任务置于“已暂停”状态。该模型快照将经过正常的安全筛查过程,之后即可在整个 OpenAI 平台中作为常规微调模型供您使用。
如果你想继续已暂停作业的训练过程,可以使用以下方式: 微调作业 API。这将从任务暂停时创建的最后一个检查点恢复训练过程,并继续训练,直到任务完成或再次暂停。
使用工具进行评分
如果你正在训练模型以 执行工具调用,您需要:
- 请在 RFT 训练数据集的每个数据点上提供模型可调用的工具集。更多信息请参见 数据集 API 参考.
- 配置你的评分器,以根据模型生成的工具调用内容来分配奖励。有关工具调用评分的信息请参见 评分文档
计费详情
强化微调作业根据训练所花费的时间以及模型在训练期间使用的 token 数量进行计费。我们仅对核心训练循环中花费的时间收费,而不对准备训练数据、验证数据集、排队等待、运行安全评估或其他开销所花费的时间收费。
有关强化微调作业具体计费方式的详细信息,请参阅此 帮助中心文章.
训练错误
强化微调是一个包含许多环节的复杂过程,很多地方都可能出现问题。我们发布了各种错误指标,以帮助您了解任务中出了什么问题以及如何修复。通常,除非发生非常严重的错误,否则我们会尽量避免任务直接失败。当错误确实发生时,通常出现在评分阶段。评分阶段发生错误,往往是因为模型输出了评分器不知道如何处理的样本,或者是评分器因某种系统错误而未能正确执行,又或者是评分逻辑本身存在 Bug。
错误指标可在 event.data.errors 对象下查看,并按每个评分器汇总为计数和比率。我们还会在微调控制台上显示错误的比率和计数。