
本指南涵盖了一套核心原则,可应用于改善各种 LLM 相关用例的延迟。这些技术源自与众多客户和开发者在生产应用上的合作,因此无论你构建什么——从细粒度工作流到端到端聊天机器人——它们都适用。
虽然有许多单独的技巧,但我们将它们归类为 七项原则 旨在代表改善延迟的高层级方法分类。
最后,我们将通过一个 示例 来看看它们如何应用。
七项原则
更快速地处理 Token
推理速度 可能是解决延迟问题时首先想到的因素(但正如您很快将看到的,这远非唯一因素)。这指的是实际的 LLM 处理 Token 的速率,通常以 TPM(每分钟 Token 数)或 TPS(每秒 Token 数)来衡量。
影响推理速度的主要因素是 模型规模 ——较小的模型通常运行速度更快(且成本更低),如果使用得当,甚至可以超越更大的模型。要在使用较小模型的同时保持高质量的性能,您可以尝试:
您还可以采用推理优化措施,例如我们的 预测输出 功能。当您提前知道大部分输出内容时(例如代码编辑任务),预测输出可以显著降低生成的延迟。通过向模型提供一个预测,LLM 可以将更多注意力集中在实际更改上,而减少对保持不变的内容的处理。
Other factors that affect inference speed are the amount of
compute you have available and any additional
inference optimizations you employ.
Most people can’t influence these factors directly, but if you’re curious, and
have some control over your infra, faster hardware or
running engines at a lower saturation may give you a modest
TPM boost. And if you’re down in the trenches, there’s a myriad of other
inference optimizations
that are a bit beyond the scope of this guide.
生成更少的 token
在使用 LLM 时,生成 token 几乎总是延迟最高的步骤:作为一般经验法则, 将输出 token 减少 50% 可能会降低约 50% 的延迟。减少输出大小的方法取决于输出类型:
如果您正在生成 自然语言,只需 要求模型更简洁 (“20 个字以内”或“尽量简短”)可能会有所帮助。您还可以使用少样本示例和/或微调来教导模型给出更简短的回复。
如果您正在生成 结构化输出,请尝试 尽量精简您的输出语法 :缩短函数名称、省略命名参数、合并参数等。
最后,虽然不常见,您还可以使用 max_tokens or stop_tokens 以提前结束生成。
请始终记住:省下一个输出 token 就等于赚回一(毫)秒!
使用更少的输入 token
虽然减少输入 token 的数量确实能降低延迟,但这通常不是一个显著因素—— 将提示词减少 50% 可能只会带来 1-5% 的延迟改善。除非您正在处理真正庞大的上下文(文档、图像),否则您可能需要将精力投入到其他方面的优化上。
话虽如此,如果您 正在 处理超长上下文(或者你致力于压榨最后一丝性能 and 你已尝试过所有其他选项),你可以使用以下技术来减少输入 token:
- 微调模型,以取代对冗长指令/示例的需求。
- 过滤上下文输入,例如修剪 RAG 结果、清理 HTML 等。
- 最大化共享提示词前缀,通过将动态部分(例如 RAG 结果、历史记录等)放在提示词靠后的位置。这会使你的请求更 KV cache友好(大多数 LLM 提供商都在使用),并意味着每次请求会处理更少的输入 token。
查看我们的文档以了解更多关于如何 提示缓存 works.
减少请求次数
每次请求都会产生一定的往返延迟——这会逐渐累积。
如果你有需要大语言模型 (LLM) 执行的连续步骤,与其每个步骤都发起一次请求,不如考虑 将它们放在单个提示词中,并在一次响应中全部获取。你将避免额外的往返延迟,并可能降低处理多个响应的复杂度。
实现此目的的一种方法是,在组合的提示词中以枚举列表的形式收集你的步骤,然后要求模型在 JSON 的命名字段中返回结果。这样你就可以轻松解析并引用每个结果!
并行处理
在使用大语言模型 (LLM) 执行多个步骤时,并行化可以发挥巨大的作用。
如果步骤 正在 并非 严格连续, 你可以 将它们拆分为并行调用。烘干两件衬衫和一件衬衫花费的时间一样长。
如果步骤 正在 严格连续,然而你可能仍然可以 利用预测执行。这对于某个结果比其他结果更有可能出现的分类步骤(例如内容审核)尤其有效。
- 同时启动步骤 1 和步骤 2(例如输入内容审核与故事生成)
- 验证步骤 1 的结果
- 如果结果不符合预期,则取消步骤 2(如有必要则重试)
如果你对步骤 1 的预测正确,那么你实际上在零额外延迟的情况下运行了它!
让用户等待更少
之间存在着巨大的差异: 等待 and 看着进度推进 ——确保你的用户体验到后者。以下是一些技巧:
- 流式传输:最有效的方法,因为它减少了 等待 时间缩短到一秒或更短。(如果在每次响应完全生成之前什么都看不到,ChatGPT 的体验将会大不相同。)
- 分块处理: 如果你的输出在展示给用户之前需要进一步处理(内容审核、翻译),请考虑 分块进行处理 而不是一次性全部返回。可以通过将其流式传输到你的后端,然后将处理后的分块发送到前端来实现。
- 展示步骤: 如果你正在执行多个步骤或使用工具,请向用户展示这一点。你能展示的实时进度越多越好。
- 加载状态:加载动画和进度条大有帮助。
请注意,虽然 展示步骤和设置加载状态 主要产生心理层面的影响, 流式传输与分块处理 一旦将应用与用户视为一个整体系统来考虑,确实能够真正降低整体延迟:用户将能更快地阅读完响应内容。
不要默认使用 LLM
LLM 非常强大且通用,因此有时会被用于某些实际上 更快的传统方法 更适合的场景。识别这些场景可能让你大幅降低延迟。请考虑以下示例:
- Hard-coding: 如果你的 输出 受到高度限制,你可能不需要 LLM 来生成它。操作确认、拒绝消息和标准输入请求都非常适合硬编码。(你甚至可以使用最古老的方法,为每种情况想出几个变体。)
- Pre-computing: 如果你的 输入 受到限制(例如分类选择),你可以提前生成多个回复,只需确保永远不要向同一用户重复展示同一个回复。
- 利用 UI: 摘要指标、报告或搜索结果,有时使用传统的定制 UI 组件来传达效果更好,而不是使用 LLM 生成的文本。
- 传统优化技术: LLM 应用本质上还是应用;二分查找、缓存、哈希映射和时间复杂度等在 LLM 时代 依然 非常有用。
示例
现在让我们看一个示例应用,找出潜在的延迟瓶颈,并提出一些解决方案!
我们将分析一个受真实生产应用启发的假设性客服机器人的架构和提示词。 架构和提示词 部分将搭建背景,而 分析与优化 部分将逐步演示延迟优化过程。
你会注意到,这个示例并没有涵盖每一个原则,就像真实的使用场景也不需要应用所有的技术一样。
架构和提示词
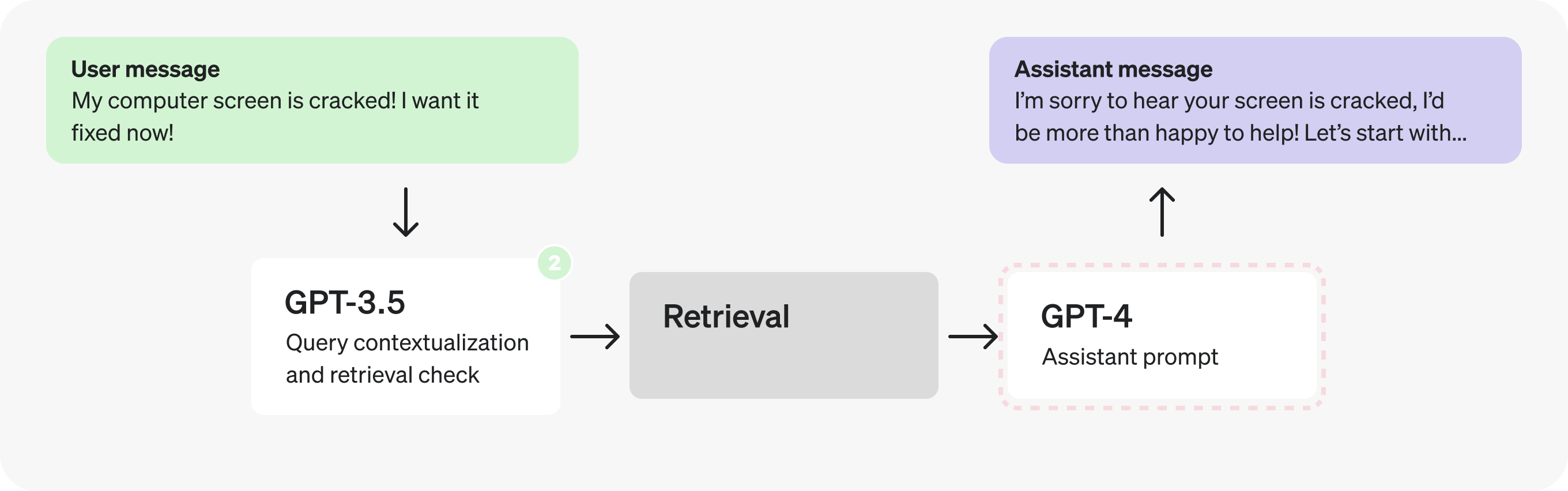
The following is the 初始架构 for a hypothetical 客服机器人。这就是我们将要修改的内容。
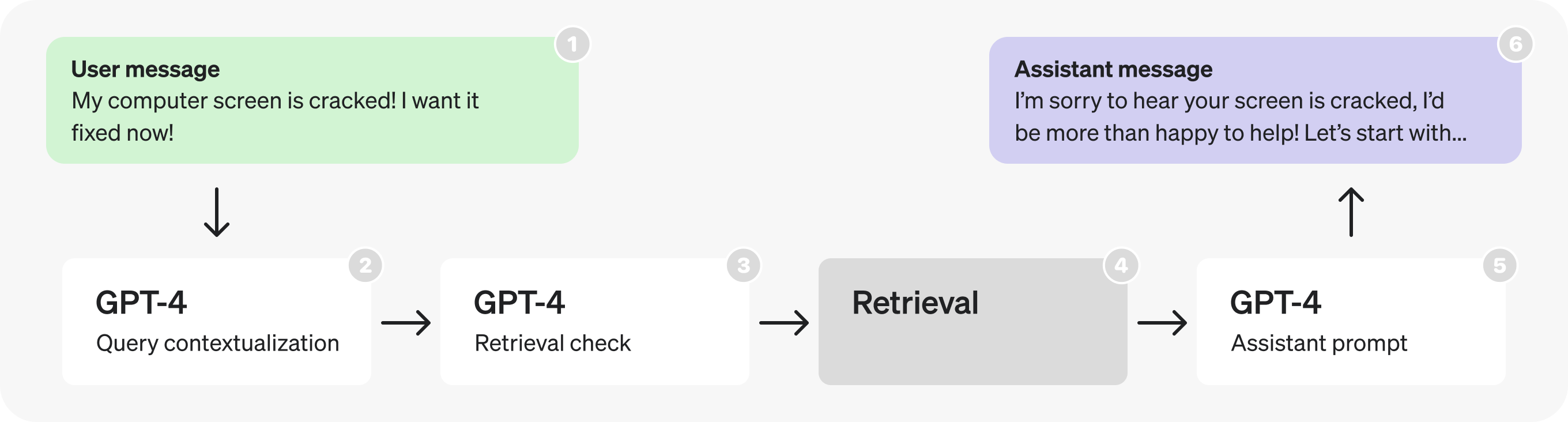
总体而言,该流程图描述了以下过程:
- 用户在持续的对话中发送一条消息。
- 最新的消息被转化为一个 独立的查询 (参见提示词中的示例)。
- 我们确定是否需要 额外的(检索到的)信息 以响应该查询。
- 检索 被执行,从而生成搜索结果。
- The assistant 原因 关于用户查询和搜索结果,并 生成响应.
- 该响应随后被发送回用户。
以下是图表各部分所使用的提示词。虽然它们目前仍是假设性且经过简化的,但其结构和措辞与你在实际生产应用中会看到的如出一辙。
你在“[此处为用户输入]”等处看到的占位符,代表动态部分,它们会在运行时被实际数据替换。
分析与优化
第 1 部分:审视检索提示词
观察该架构,首先引人注目的是 连续的 GPT-4 调用 ——这暗示了潜在的低效问题,通常可以通过单次调用或并行调用来替代。
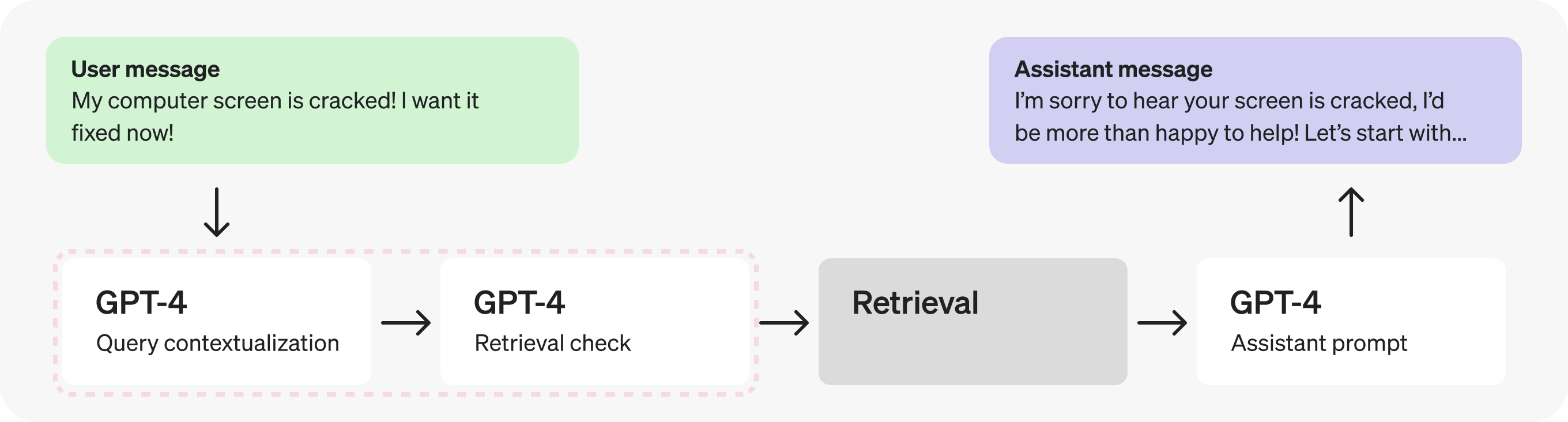
在这种情况下,由于检索判断需要用到上下文化后的查询,让我们 将它们合并到一个提示词中 to 减少请求数量.
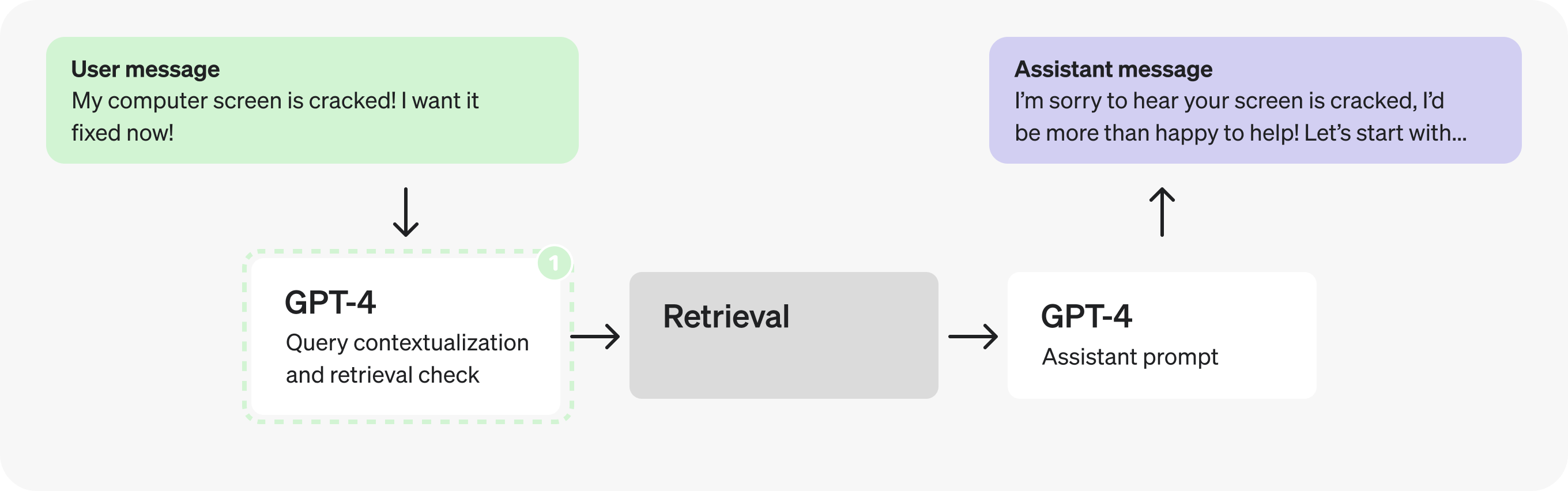
实际上,添加上下文和判断是否需要检索是非常简单且明确的任务,因此我们很可能可以使用 更小的微调模型 来代替。切换到 GPT-3.5 将使我们能够 更快地处理 token.
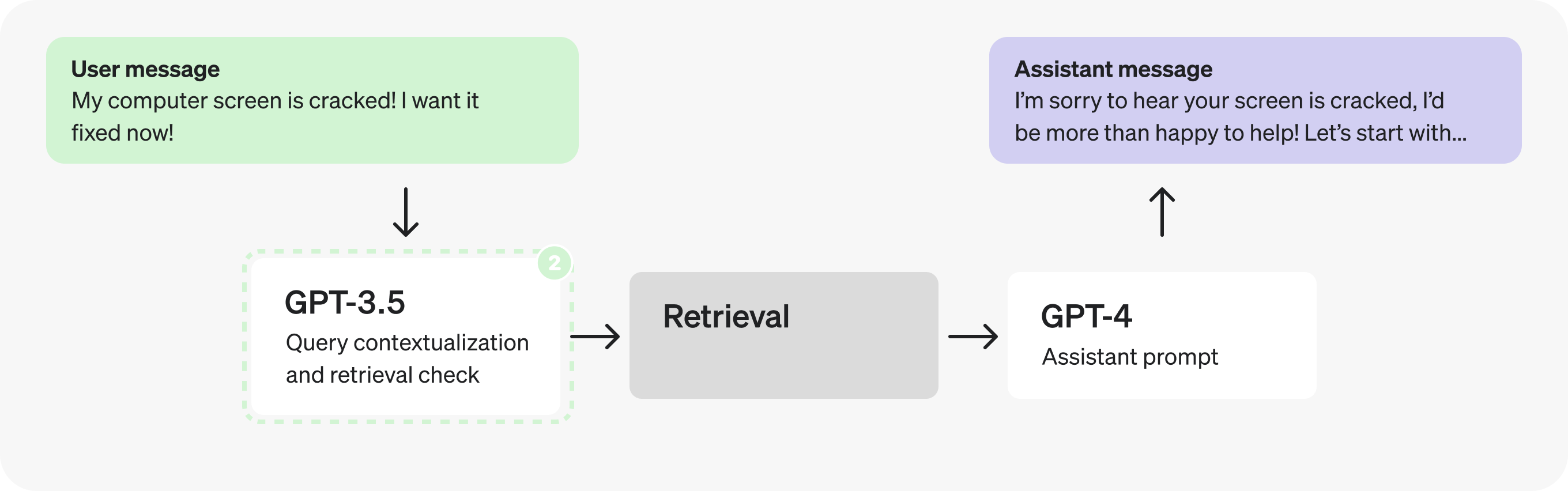
第二部分:分析助手提示词
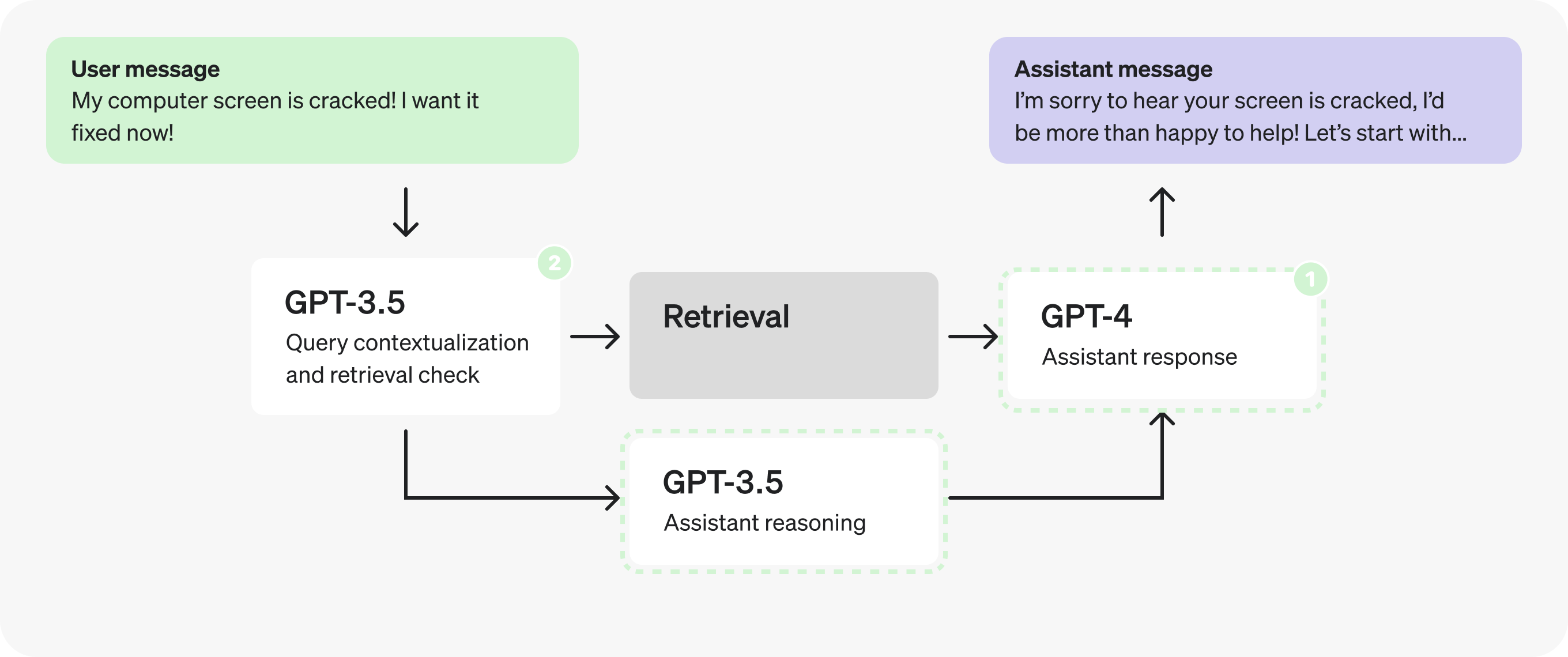
现在让我们把注意力转向助手提示词。在填充 JSON 字段的过程中,似乎有许多不同的步骤正在执行——这可能意味着我们有机会 并行化.
不过,我们假设已经进行了一些测试,并发现拆分 JSON 中的推理步骤会导致响应质量下降,因此我们需要探索其他的解决方案。
我们可以使用微调过的 GPT-3.5 来代替 GPT-4 吗? 也许可以——但通常来说,将助手开放式回复交由 GPT-4 处理效果更好,因为它能更好地应对更广泛的情况。话虽如此,观察推理步骤本身,可能并非所有的步骤都需要 GPT-4 级别的推理能力才能生成。其定义明确且范围有限的特性使得它们成为 进行微调的理想候选者.
1
2
3
4
5
6
7
8
9
10
11
{
"message_is_conversation_continuation": "True", // <-
"number_of_messages_in_conversation_so_far": "1", // <-
"user_sentiment": "Aggravated", // <-
"query_type": "Hardware Issue", // <-
"response_tone": "Validating and solution-oriented", // <-
"response_requirements": "Propose options for repair or replacement.", // <-
"user_requesting_to_talk_to_human": "False", // <-
"enough_information_in_context": "True", // <-
"response": "..." // X -- benefits from GPT-4
}这就提供了一种权衡的可能。我们是将其保留为 完全由 GPT-4 生成的单一请求, or 拆分为两个顺序请求 并使用 GPT-3.5 处理最终响应之外的所有内容?我们面临着原则冲突的情况:第一种方案使我们能够 减少请求数量, 但第二种方法可能让我们 更快地处理 token.
与许多优化权衡一样,答案取决于具体的细节。例如:
- 中 token 的比例
response与其他字段中的 token 比例。 - 通过更快地处理大多数字段而减少的平均延迟。
- The average latency 增加 ,这是因为执行了两次请求而不是一次。
结论会因具体情况而异,做出决定的最好方法是使用生产环境的示例进行测试。在这个例子中,我们假设测试结果表明将提示词一分为二是更有利的: 更快地处理 token.
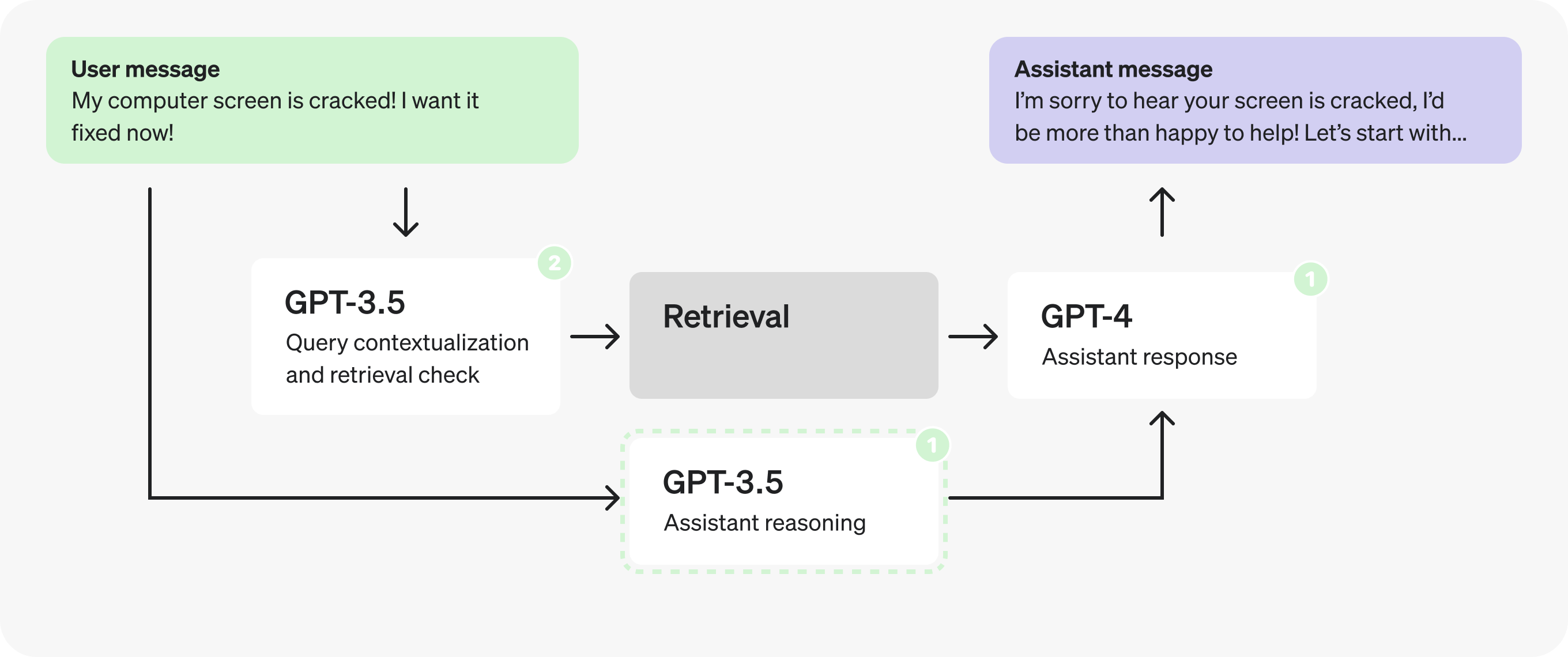
Note: 我们将把 response and enough_information_in_context 组合在第二个提示词中,以避免将检索到的上下文传递给两个新提示词。
事实上,既然推理提示词不再依赖于检索到的上下文,我们可以 并行化 ,并与检索提示词同时发出。
第 3 部分:优化结构化输出
让我们再看一下推理提示。
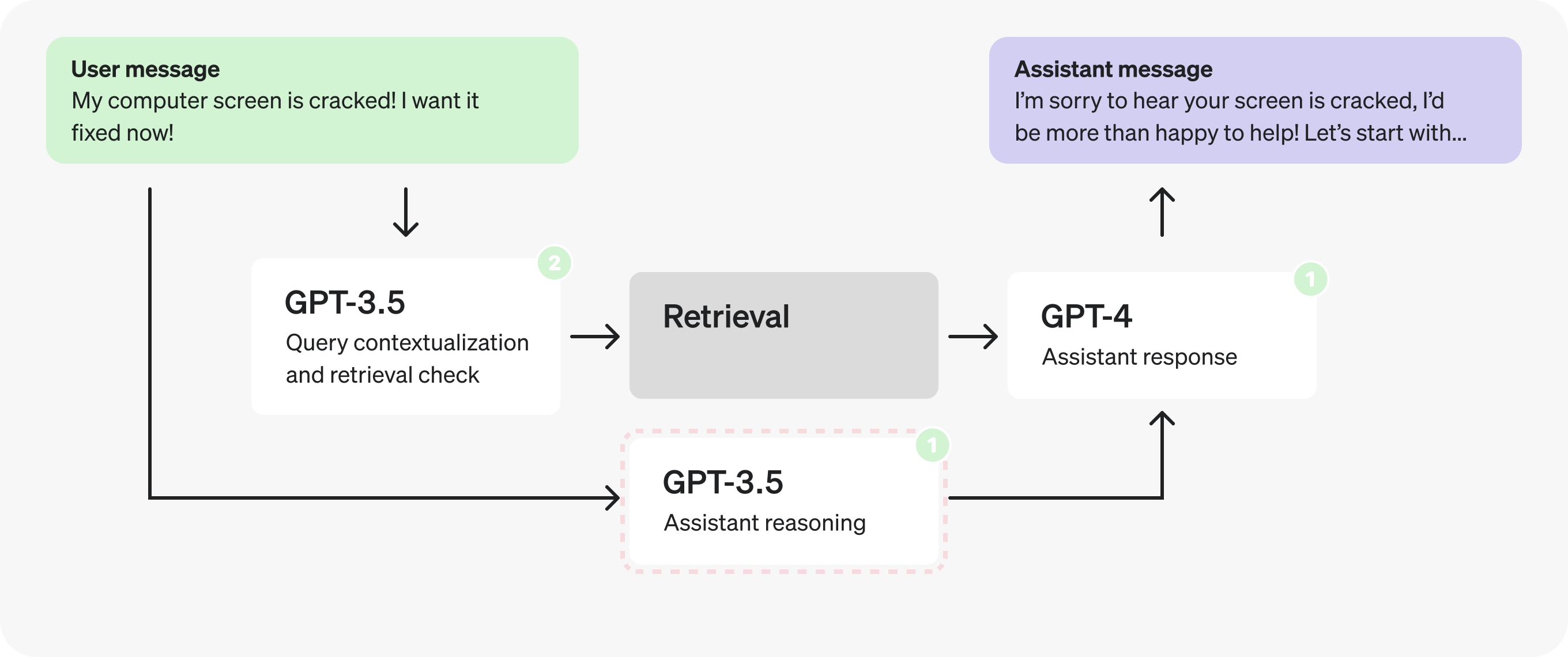
仔细观察推理 JSON,你可能会注意到字段名称本身相当长。
1
2
3
4
5
6
7
8
9
{
"message_is_conversation_continuation": "True", // <-
"number_of_messages_in_conversation_so_far": "1", // <-
"user_sentiment": "Aggravated", // <-
"query_type": "Hardware Issue", // <-
"response_tone": "Validating and solution-oriented", // <-
"response_requirements": "Propose options for repair or replacement.", // <-
"user_requesting_to_talk_to_human": "False", // <-
}通过将它们缩短并将解释移至注释中,我们可以 生成更少的 token.
1
2
3
4
5
6
7
8
9
{
"cont": "True", // whether last message is a continuation
"n_msg": "1", // number of messages in the continued conversation
"tone_in": "Aggravated", // sentiment of user query
"type": "Hardware Issue", // type of the user query
"tone_out": "Validating and solution-oriented", // desired tone for response
"reqs": "Propose options for repair or replacement.", // response requirements
"human": "False", // whether user is expressing want to talk to human
}
这一小改动减少了 19 个输出 token。虽然对于 GPT-3.5,这可能只会带来几毫秒的提升,但对于 GPT-4,这可能节省多达一秒的时间。

然而你可以想象,对于更大的模型输出,这会产生相当显著的影响。
我们可以更进一步,为 JSON 字段使用单字符,或者将所有内容放入数组中,但这可能会开始损害我们的响应质量。再次强调,了解这一点的最佳方法是通过测试。
示例总结
让我们回顾一下为客户服务机器人示例实施的优化:
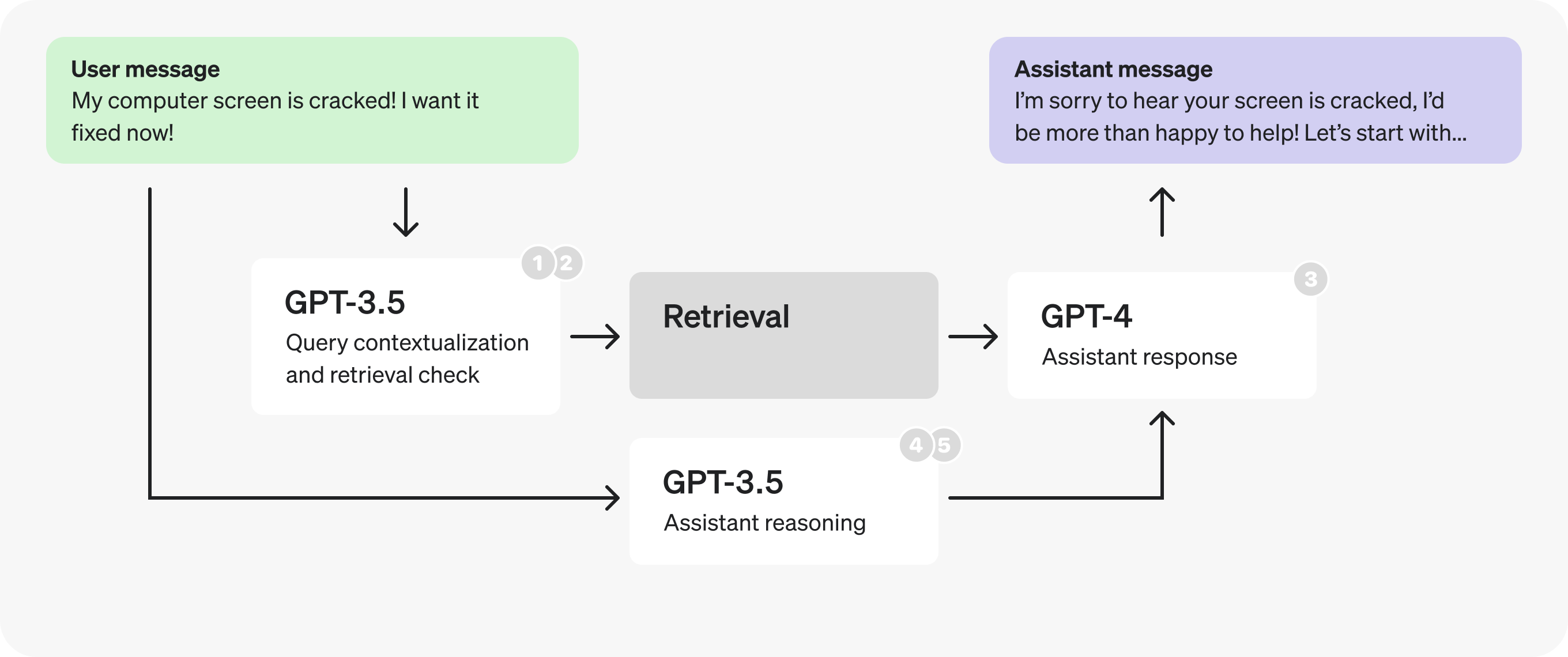
- 合并了 查询上下文化和检索检查步骤以 减少请求数量.
- For the new prompt, 切换到更小的、经过微调的 GPT-3.5 to 更快地处理 token.
- 将助手提示一分为二, 切换到更小的、经过微调的 GPT-3.5 用于推理,再次 更快地处理 token.
- 并行化 检索检查和推理步骤。
- 缩短推理字段名称 并将注释移至提示中,以 生成更少的 token.